
Introduction
I recently attended a peer conference where I presented my experience report on regression testing. I’m going to go into the detail of what I talked about in this post - if you’d like to read more about the peer conference and what on earth a ‘peer conference’ even is, read here:
NWEWT #1 Regression Testing
NWEWT #1 Regression Testing
Disclaimer
I have no data to back this up, before I go any further I’d like to highlight that. What I state here is my opinion based on observations and my interpretation of people’s words and actions. I’ve not really thought about how I might go about measuring and collecting data to back up my words here, but I’m going to bear it in mind for future topics!
Feelings of mis-use
For the last 6 years of my testing career I’ve never been formally trained on testing. I don’t have an ISTQB qualification and a lot of what I know about testing I have either been informally trained or I have learnt myself from observing others. I therefore have a definition of ‘regression testing’ that I have learnt from how others use it.
Before I go into what I personally define this phrase to mean, I’ve noticed ‘regression testing’ referred to as:
“The testing we perform at the end of projects, where we re-run all of our tests and make sure the code hasn’t broken anything.”
This kind of understanding also seemed to crop up and become twisted with statements like:
“I’d like to press a button and run all of the regression tests automatically.”
“Why didn’t your regression tests find this?”
After being invited to the peer conference, I decided to look up the wikipedia definition of ‘regression testing’. I went with wikipedia simply because it’s likely to be a commonly used source. I actually found that wikipedia’s definition fits my own definition fairly well:
“Regression testing is a type of software testing that verifies that software that was previously developed and tested still performs correctly after it was changed or interfaced with other software.”
Combining this definition with my recent understanding that ‘testing’ is about learning, I think this fits with my own take on ‘regression testing’ which would be:
“Regression testing is considering the risk of change”.
Comparing my own definition with how people seem to use the phrase, I realised people seemed to define regression testing with the attributes of:
- Repeating tests and therefore being highly automated.
- Being performed late in a project, at the end of a sprint or a waterfall. Usually it seemed like it was considered an activity to be performed after development activities.
This seemed totally wrong to me, and I started thinking about why I felt that.
Why does this matter?
Well the first question I felt I needed to answer is - why does it matter people have these differing definitions? Well, this is what I could think of:
- If regression testing is only performed at ‘the end’, does that mean we only consider the risk of change at the end?
- If regression testing is an activity to be carried out after development activities, how invested are non-testers in the results?
- If we are only performing regression testing at the end, and therefore only considering it later, how do we effectively identify risks?
- Assumptions are being made about how valuable it is to repeat tests and the cost of executing them.
In Practice
In my opinion, everyone involved with software development is considering the risk of change all of the time even if only subconsciously. Typically, we’re nearly always changing the software and hence discussing what the desired behaviour is. However, for me the danger of the phrase ‘regression testing’ and how it seems to be commonly used is that we’re leaving the bulk of this kind of critical thinking to the end of projects. Not to mention over-estimating the value of simply repeating tests over and over.
Could we be finding problems with change earlier? When it’s cheaper to both identify and act upon?
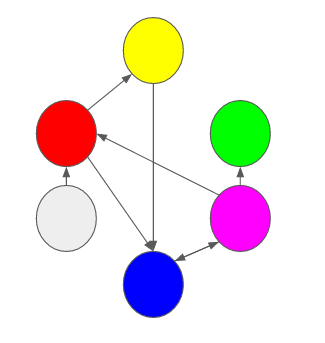
What if we are developing a component that is part of a larger system, are we not considering the risk of change as we develop it in isolation? As we start integrating it? Is it wise to only to consider the greater implications of a change later on?
What if we’re developing a change to the red component, are we only going to consider its integration with the blue component later? What about the effects of this change to the components that are not directly connected like the green one?
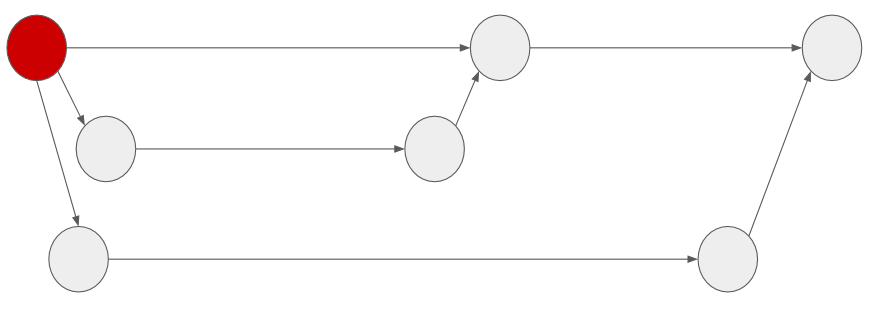
With git branching, where do you perform ‘regression testing’ here? Who performs the testing? How do they identify when and what to test? When is ‘at the end’? What tests would you run ‘at the end’? Are you only repeating tests? Or running new tests?
These questions are hard to answer when you don’t have all of the information available to you, with these git branches you may not know what was changed as part of each branch - you may not even know how many branches there are and when they were merged. The developer who is writing each change and merging it knows this, but do they identify the risks? Or do they ‘leave it for regression testing’?
My conclusions
I’m concerned that ‘regression testing’ is being referred to as a standard testing phase, different to the testing carried out as part of development activities. This seems wrong to me because it encourages the ‘over the fence’ mentality of ‘coders code, testers test’. If we are to effectively identify the risks of change, we need to work together as a team, not as separate roles.
I believe regression testing is a continuous activity that should be performed as soon as possible. The reason it may have to be performed ‘at the end’ is not because it should be, but because that is the earliest possible point. I currently work in an environment which desires a ‘lean agile’ approach (speed) at the same time as developing a microservices architecture (decoupled). Both of these require us to become smarter with our testing, we don’t have time to run large numbers of repeated tests just before releasing only to find out a flaw in our work that could have been realised with some greater collaboration earlier on.Finally, regression testing is not an automatable activity - it is the process of consideration and analysis, not repetition. Repeating a test may be useful to help us evaluate risk, but sometimes we may want to try a totally new test. Regression testing isn’t just repeating all of the tests that were run before - as the risk changes, so do your tests. Your testing needs to be continuously adapted to this changing risk.
Thanks for sharing your experience report Matt. Your session definitely got the group excited & it was interesting to see where the discussion went.
ReplyDeleteNice disclaimer - that's part of the reason for using experience reports. It's what we've experienced but can't yet map back to data. We're hoping others can help smash or reinforce our ideas
Duncs